Pandas Append to Csv Without Reading Whole Dataframe Into Memory
Even when we take 1TB of Disk Storage, 8GB/16GB of RAM all the same pandas and much other data loading API struggles to load a 2GB file.
This is because when a process requests for retentiveness, retentivity is allocated in two means:
- Contiguous Retention Allocation (consecutive blocks are assigned)
- Non Contiguous Memory Resource allotment(separate blocks at different locations)
Pandas use Contiguous Memory to load data into RAM because read and write operations are must faster on RAM than Disk(or SSDs).
- Reading from SSDs: ~16,000 nanoseconds
- Reading from RAM: ~100 nanoseconds
Before going into multiprocessing & GPUs, etc… let us meet how to use pd.read_csv() finer.
Pandas is fine for loading data and preprocessing but to train your models start using DataLoader from TensorFlow or PyTorch or where ever yous run your model.
Note: If you are reading in your mobile yous may non exist able to gyre through the code. (Open up the Gist for better readability.)
1. use cols:
Rather than loading data and removing unnecessary columns that aren't useful when processing your information. load only the useful columns.
2. Using correct dtypes for numerical data:
Eve r y column has it's own dtype in a pandas DataFrame, for example, integers accept int64, int32, int16 etc…
-
int8can store integers from -128 to 127. -
int16can store integers from -32768 to 32767. -
int64tin can store integers from -9223372036854775808 to 9223372036854775807.
Pandas assign int64 to integer datatype past default, therefore past defining correct dtypes we can reduce retentiveness usage significantly.
🔥 Pro Tip: Use converters to supplant missing values or NANs while loading data, especially for the columns that take predefined datatypes using dtype.
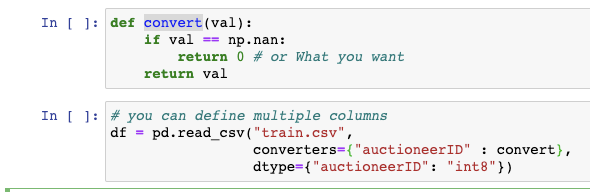
3. Using correct dtypes for categorical columns:
In my Dataset, I take a column Pollex which is past default parsed as a string, but information technology contains but a stock-still number of values that remain unchanged for whatever dataset.
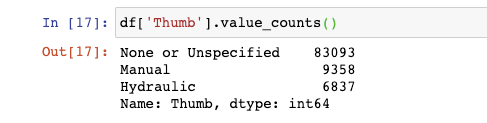
And also columns such as Gender, etc.. can exist stored as categorical values which reduces the memory from ~chiliad KB to ~100 KB. (check the sats)
🔥 Pro Tip: If your DataFrame contains lots of empty values or missing values or NANs y'all tin reduce their retentiveness footprint by converting them to Sparse Series.
iv. nrows, skip rows
Even before loading all the information into your RAM, it is always a skillful practice to test your functions and workflows using a small dataset and pandas have made it easier to choose precisely the number of rows (you lot tin even skip the rows that you do non demand.)
In most of the cases for testing purpose, you don't need to load all the data when a sample can do just fine.
nrows The number of rows to read from the file.
>>> Import pandas every bit pd
>>> df = pd.read_csv("train.csv", nrows=chiliad)
>>>len(df)
1000 skiprows Line numbers to skip (0-indexed) or the number of lines to skip (int) at the start of the file.
# Can be either list or start Due north rows.
df = pd.read_csv('train.csv', skiprows=[0,ii,5])
# It might remove headings 🔥 Pro-Tip: An Effective employ of nrows is when you accept more than 100'due south of columns to check and define proper dtypes for each and every column. All of this overhead tin exist reduced using nrows as shown beneath.
sample = pd.read_csv("train.csv", nrows=100) # Load Sample data dtypes = sample.dtypes # Get the dtypes
cols = sample.columns # Get the columns dtype_dictionary = {}
for c in cols:
"""
Write your own dtypes using
# rule 2
# rule 3
"""
if str(dtypes[c]) == 'int64':
dtype_dictionary[c] = 'float32' # Handle NANs in int columns
else:
dtype_dictionary[c] = str(dtypes[c]) # Load Information with increased speed and reduced memory.
df = pd.read_csv("train.csv", dtype=dtype_dictionary,
keep_default_na=False,
error_bad_lines=Imitation,
na_values=['na',''])
Annotation: Equally NANs are considered to exist float in pandas don't forget to convert integer data_types to float if your columns incorporate NANs.
five. Loading Information in Chunks:
Memory Issues in pandas read_csv() are there for a long time. So one of the best workarounds to load large datasets is in chunks.
Note: loading data in chunks is really slower than reading whole information direct every bit you demand to concat the chunks again but you tin can load files with more than 10's of GB'due south easily.
6. Multiprocessing using pandas:
Every bit pandas don't have njobs variable to make apply of multiprocessing ability. we tin utilize multiprocessinglibrary to handle chunk size operations asynchronously on multi-threads which can reduce the run fourth dimension by one-half.
Note: yous need to ascertain
puddlein __main__ only because only primary can distribute pool asynchronously amidst multiple processers.
7. Dask Instead of Pandas:
Although Dask doesn't provide a wide range of data preprocessing functions such every bit pandas information technology supports parallel computing and loads information faster than pandas
import dask.dataframe as dd data = dd.read_csv("train.csv",dtype={'MachineHoursCurrentMeter': 'float64'},assume_missing=Truthful)
data.compute()
🔥Pro Tip: If y'all want to discover the time taken by a jupyter cell to run just add together %%time magic part at the start of the jail cell
Libraries to try out: Paratext , Datatable .
Their'south is an another fashion, Y'all can rent a VM in the cloud, with 64 cores and 432GB RAM, for ~$3/hr or even a better toll with some googling.
caveat: you lot need to spend the next week configuring it.
Cheers for reaching until the end, I hope you learned something new. Happy Loading….✌️. (👏 If you lot like information technology.)
Comment below the tricks that you lot used to load your information faster I will add together them to the list.
References(Add together them to your blog list):
🔥 Itamar Turner-Trauring — Speed Python Primary (Must ✅).
🔥 Gouthaman Balaraman — quantitative finance with python (Must ✅).
Connect with me on Linkedin.
Source: https://towardsdatascience.com/%EF%B8%8F-load-the-same-csv-file-10x-times-faster-and-with-10x-less-memory-%EF%B8%8F-e93b485086c7
0 Response to "Pandas Append to Csv Without Reading Whole Dataframe Into Memory"
Post a Comment